

Source Code is Obsolete: The Rise of Direct-to-Binary AI Synthesis
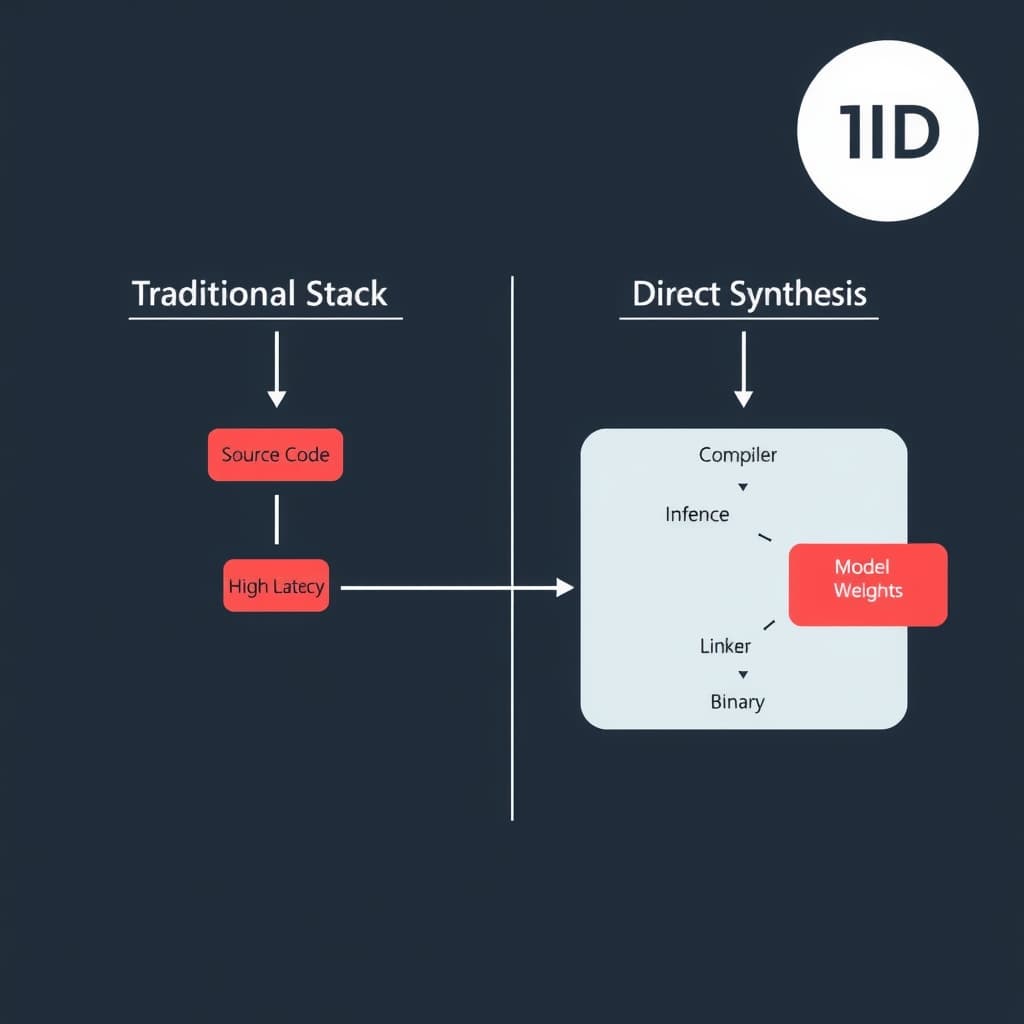
The belief that software must remain human-readable is a sentimental bottleneck, not a technical requirement. For decades, we have accepted a massive inefficiency in our computing stack: the requirement that instructions be legible to humans (source code) before being translated into the language of the machine (binary). We treat code as literature, maintaining vast repositories of text files that must be parsed, tokenized, optimized, and linked by compilers that—while impressive—rely on generalized heuristics rather than context-specific optimality.
Direct-to-Binary AI Synthesis proposes a radical architectural shift: training Large Language Models (LLMs) and Transformer architectures on Instruction Set Architectures (ISAs) like x86-64 or ARM64, rather than high-level syntax like C++ or Rust. By predicting opcodes instead of keywords, we eliminate the "translation loss" inherent in compilation. This is not merely about coding faster; it is about achieving hardware utilization rates that are mathematically impossible through traditional compiler logic.
Bypassing the Compiler: How Neural Networks Speak Machine Code
The current software supply chain is built on the assumption that a deterministic translator (the compiler) is the only safe way to produce an executable. However, compilers are constrained by safety guarantees and generalized optimization passes that must work for all code, not just your code.
The Computational Cost of Abstraction Layers
Every layer of abstraction—from Python to C, from C to Assembly—introduces overhead. A compiler like LLVM translates source code into an Intermediate Representation (IR), applies optimization passes, and then lowers it to machine code. While efficient, this process is bound by rigid logic. It cannot "improvise."
for loop iterates, the model learns that a specific sequence of CMP (compare) and JNZ (jump if not zero) instructions alters the instruction pointer and register values. By training on the raw execution traces and binary dumps, the model learns the physics of the silicon directly. This allows the AI to discover non-obvious optimizations—such as abusing specific register side-effects or instruction-level parallelism—that a compiler's rigid safety checks would fundamentally reject.Training Transformers on Instruction Set Architectures (ISA)
The technical implementation involves tokenizing hex dumps rather than ASCII text. In this paradigm, the vocabulary size shifts from the roughly 50,000 tokens of a standard English/Code LLM to the discrete instruction set of the target architecture.
NameError. In binary, hallucinating a bit creates an invalid opcode that crashes the process or, worse, introduces a silent memory corruption. To mitigate this, the inference layer must be constrained by a formal verification module—a "syntax checker" for binary—that ensures the output is a valid graph of executable instructions before it ever touches the CPU.The Efficiency Imperative: Why Tech Giants Demand Zero-Overhead Execution
The driving force behind this shift is not developer convenience; it is data center economics. As Moore’s Law slows, performance gains must come from software efficiency.
Case Study: DeepMind’s AlphaDev and the Sort Kernel
The precursor to full Direct-to-Binary synthesis is already here. In a landmark implementation, Google DeepMind’s AlphaDev system bypassed high-level languages to optimize sorting algorithms at the assembly level.
AlphaDev did not write C++; it played a game where the "moves" were assembly instructions (x86). It discovered a sequence of instructions for sorting small arrays that was roughly 70% faster for short sequences than the standard library implementation used by C++ for over a decade.
Comparison of Optimization Approaches:std::sort billions of times daily, this micro-optimization translates into megawatts of energy saved.Eliminating Translation Loss
x = y * 2, the compiler often converts this to a bit-shift operation because it’s faster than multiplication. This is a simple heuristic. However, in complex vector math or cryptographic kernels, the gap between "what the developer wrote" and "the optimal instruction sequence" widens. Direct synthesis removes the developer's intent from the equation entirely, optimizing solely for the final state of the registers.The Black Box Dilemma: Auditing Software Without Source Code
The most significant trade-off in this architecture is the total loss of interpretability. If the "source code" is a set of 70 billion neural network weights, traditional software engineering practices collapse.
The Obsolescence of Git and Pull Requests
git diff a neural network. In a Direct-to-Binary world, the concept of a "Pull Request" changes from reviewing logic to reviewing constraints. Engineers will no longer argue about variable naming or code style. Instead, the review process will focus on the prompt (the functional specification) and the test suite (the verification boundary).Version control becomes a lineage of model checkpoints and datasets. If a binary behaves incorrectly, you cannot "fix the code" in a text editor. You must adjust the training data or the reward function and re-synthesize the binary. This shifts the engineering discipline from construction (writing code) to curation (managing the inputs that generate code).
Security Forensics and Reverse Engineering
Security becomes a massive challenge. Traditional Static Application Security Testing (SAST) tools parse source code to find vulnerabilities. Without source code, we are left only with Dynamic Analysis (DAST) and binary forensics.
We will likely see the rise of "Neural Decompilers"—AI models trained specifically to reverse-engineer the hallucinations of other AIs, attempting to explain in human-readable pseudocode what the synthesized binary is doing. However, this adds a layer of uncertainty: we are trusting one AI to explain the black-box actions of another.
From Software 2.0 to 3.0: The Operational Roadmap (2026-2030)
We are not going to delete GitHub tomorrow. The transition to binary synthesis will be hybrid and gradual, targeting the "hot path" of execution first.
Hybrid Transition: Kernels First
By 2026, we will see Direct-to-Binary synthesis applied to kernels—small, computationally intensive loops used in video processing, high-frequency trading (HFT), and tensor math. These components have clear inputs/outputs and require maximum performance.
- Phase 1 (2025-2027): AI optimizes inline assembly within C++/Rust projects (similar to AlphaDev).
- Phase 2 (2027-2029): "Black Box" binaries are linked into standard applications. Developers call a function
fast_matrix_mul()which has no source code, only a synthesized binary blob. - Phase 3 (2030+): Operating System drivers and embedded firmware begin to be synthesized directly to reduce footprint and latency.
The Evolving Role of Engineers
The engineer's role shifts from "Syntax Writer" to "Constraint Architect." The skill set will move away from memorizing standard libraries toward formal verification and system design. You won't write the sorting algorithm; you will write the mathematical proof that ensures the synthesized sorting algorithm actually sorts.
Falsifiable Prediction
Claim: By 2028, at least one major high-frequency trading (HFT) firm or hyperscale cloud provider will publicly admit to using "source-less," AI-synthesized binary kernels for their core execution loops to gain nanosecond-level advantages.
Indicators to Watch:- Job Postings: A spike in demand for "Binary Analysis" and "Formal Verification" roles at HFT firms, coinciding with a drop in "C++ Optimization" roles.
- Tooling: The release of "Neural Assemblers" or binary-generation plugins for LLVM by major tech companies.
- Regulation: New compliance frameworks from bodies like the SEC or ESMA addressing "nondeterministic algorithms" where source code does not exist for audit.
Conclusion
Direct-to-binary synthesis represents the ultimate architectural trade-off: we are surrendering human interpretability for raw machine efficiency. As hardware complexity outpaces human cognitive limits, the ability to write directly to the metal—bypassing the leaky abstractions of high-level languages—will define the next era of high-performance computing. We are moving from a world where we tell the machine how to do something, to a world where we tell it what we want, and the machine decides the how at the transistor level.
FAQ
How do we debug AI-generated binaries without source code? Debugging shifts from reading code to analyzing behavior and reverse engineering. We will likely see the rise of "neural debuggers" that map binary execution paths back to the high-level intent or prompt used to generate them, essentially providing a "why" for the crash rather than a "where."
Will Direct-to-Binary replace languages like Python or C++? Not immediately for general business logic. The initial adoption will target performance-critical components (kernels, drivers, codecs) where the overhead of high-level languages is unacceptable. Business logic, UIs, and CRUD APIs will remain in human-readable formats for the foreseeable future due to the need for rapid iteration and maintainability.
Sources
Related
View all →



